判別分析とは?活用方法や具体的な手順をわかりやすく解説
2021年10月22日
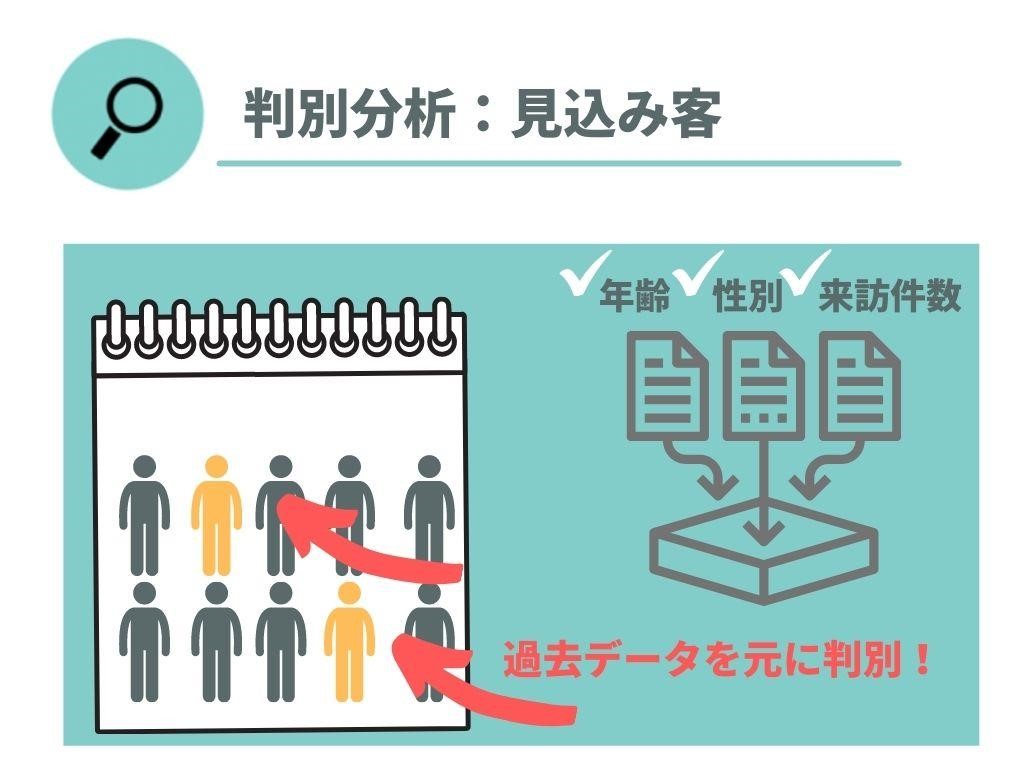
「この顧客は、自社製品を買うか?買わないか?」
判別分析では、例えば、既存のデータから「リピーター」や「単価の高い顧客」の特性を割り出し、その基準に新しい顧客情報をあてはめることで「リピーターになりそうか?単価が高くなりそうか?」などを判別することが出来ます。
本記事では、判別分析とは何かという基本的な内容からビジネスにどう活用できるのかまでわかりやすく解説します。
判別分析とは
判別分析とは、既存データの分布からデータ分類の基準(判別関数)を導き出し、未知のデータを分類するための手法です。 判別分析によりデータを分類する基準が分かることで、分析以後に得られた未知のデータについてもどのグループに分類されるのか判別できるようになります。
◆判別分析が有効な例
- 自社のリストにある見込み客のうち商品を購入する可能性が高い顧客を判別したい。
- 実際に過去商品を購入した顧客の属性(年齢、性別、過去のWEBサイトへの来訪件数)が一定数相当数データとして残っている。
上記の場合、過去商品を購入した顧客の属性を調査し判別分析をかけることで、商品を購入する可能性の高い顧客を割り出すことが可能になります。
判別分析は結果が視覚的に把握しやすいためによく使われている分析手法ですが、行うためには、以下の条件があります。
◆判別分析を行う条件
- 結果の分かっているデータが一定数存在する
- データの結果から新規データを分析できる境界線がある
- 結果が2値(例えば、購入する/購入しないなど)で判断できる
判別分析が活用されるシーン
判別分析は、以下のような場面で活用できます。
◆判別分析の活用シーン
- リピーターを判断する
- 見込み客の優先順位をつける
- レスポンス広告の顧客属性を調べる
- 併せ買いされやすい商品をレコメンドする
判別分析によって、どういった属性の顧客がリピーターになり得るかや商品購入の可能性が高い層を割り出すことで、注力すべき属性に向けた施策を行うことができます。
レスポンス広告がどういった顧客層に刺さりやすいかも割り出せば、CPAの削減にも役立つでしょう。
ネットショッピングなどで利用されているレコメンド機能やコンビニなどで展開される抱き合わせ販売形式でも判別分析が使用されています。
ビジネス以外でも、過去の世論調査に照らして候補者を当選予測したり、模試の結果から志望校への合格率を予測したりすることにも活用されています。
判別分析の算出方法
事例をもとに判別分析の算出方法の簡単な概要を説明します。
ここでは、対象生徒AがB高校に受かるのかを例にして考えてみましょう。 対象生徒Aは、中学3年生・通知表平均評価3・期末テスト点数300点というステータスであると仮定します。
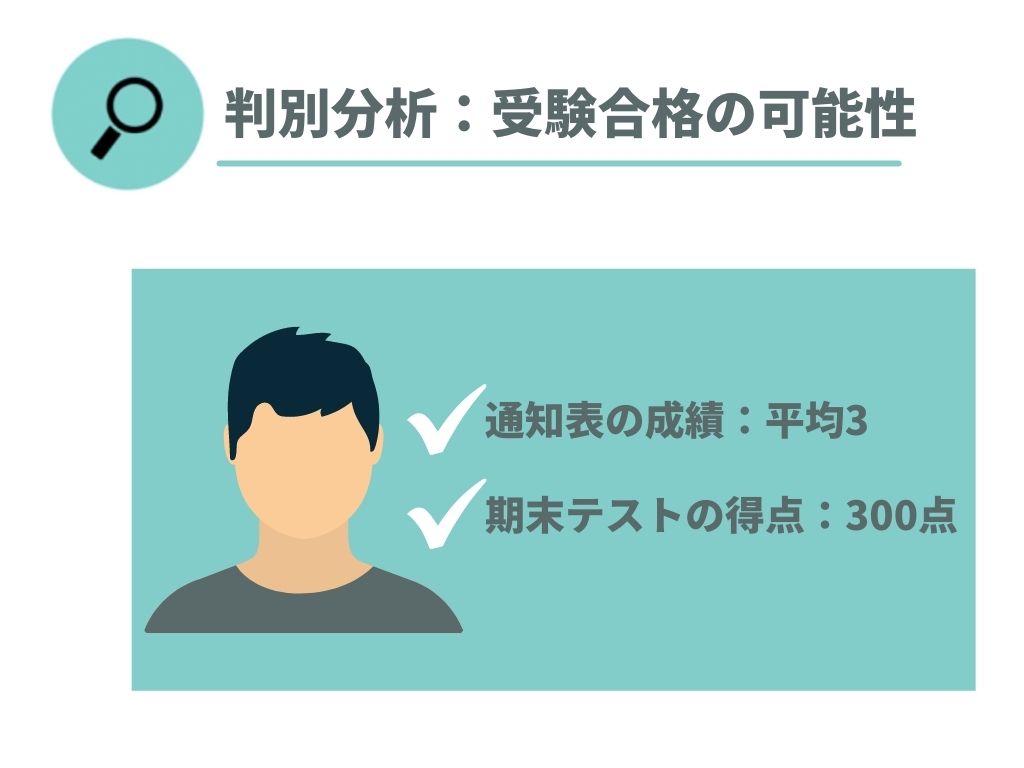
参照する過去データは、B高校を受験し、成功した人と失敗した人のデータです。 これら全ての過去データには、通知表平均評価と期末テストの点数のデータが揃っており、過去の期末テストのレベルはおおよそ同様のレベルだったものとします。
判別分析をするためには、過去データを分析する必要があります。横軸を通知表の成績、縦軸を期末テストの得点として過去データを分析します。
過去合格した人のプロットを赤、不合格だった人のプロットを青として2次元のデータにまとめ直すと以下のようになりました。
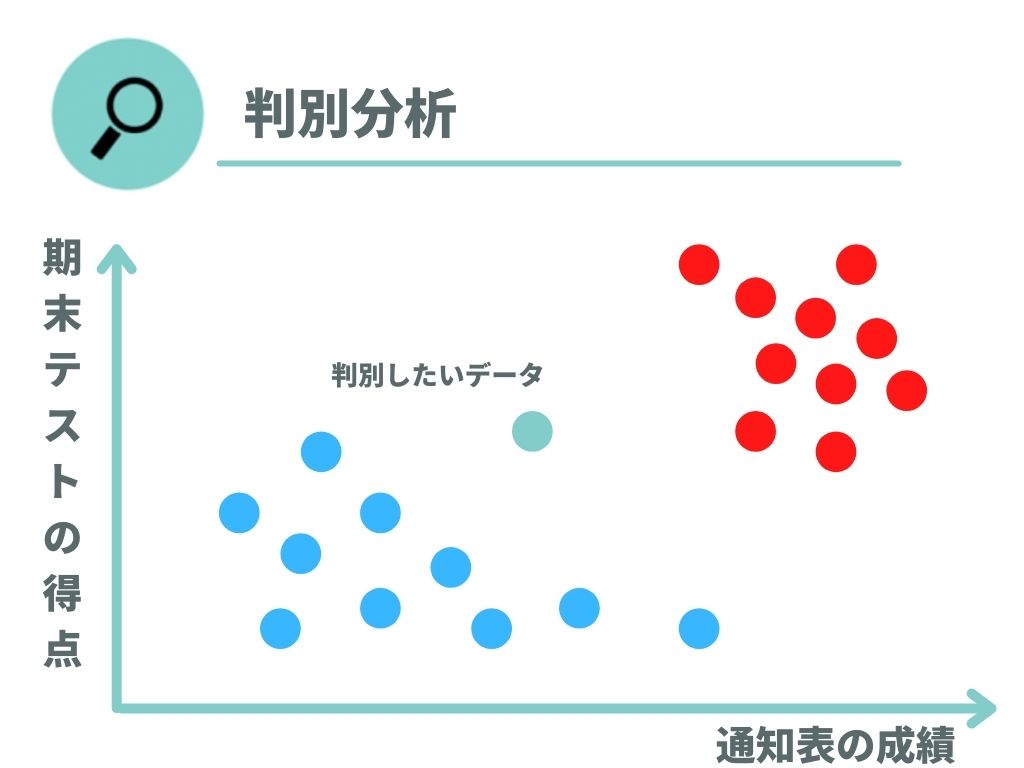
過去データと対象のデータをプロットしましたが、このままでは判別分析のどちらに入るのかがよくわかりません。
そこで利用するのが、以下2つの方法です。
マハラノビス距離で仕切る
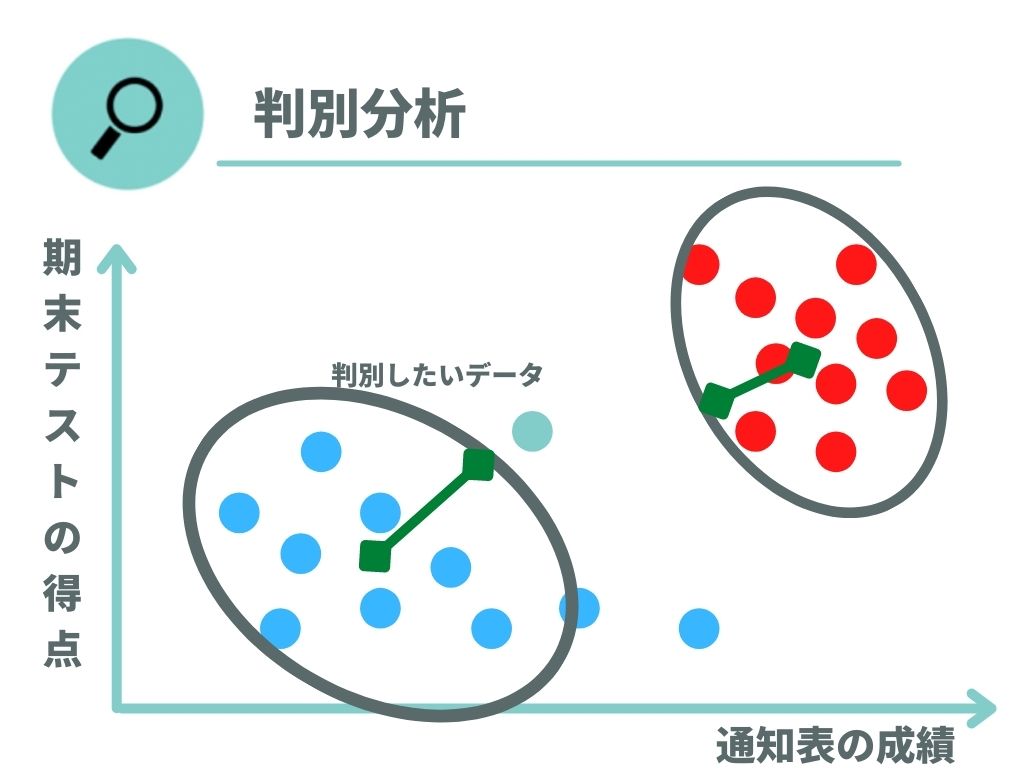
マハラノビス距離とは、単純な直線の距離(ユークリッド)ではなく分散を加味した距離で仕切る方法です。
マハラノビス距離は単純な直線ではないため、見た目上の距離と実際の距離とは異なることに注意しましょう。
マハラノビス距離で仕切ることによって、判別データは青のプロット(不合格)に近いと判断できるので「受験者は不合格の傾向が高い」と予測できます。
線形判別関数で仕切る
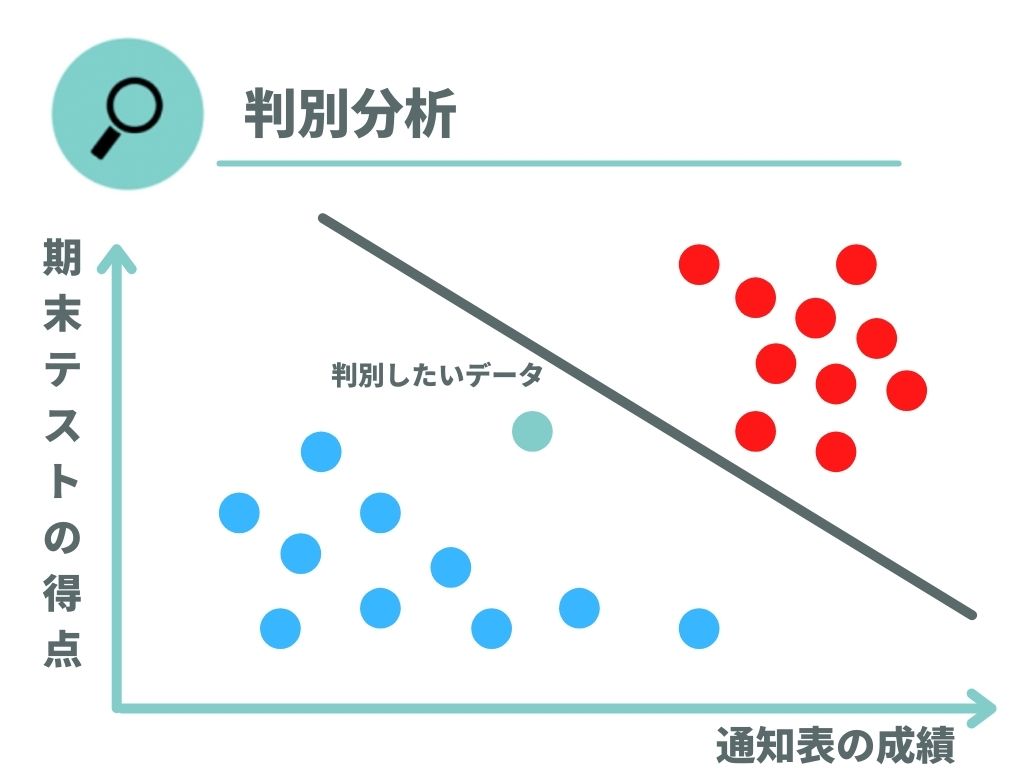
結果としてはマハラノビス距離を利用した判別分析と大きく変わりませんが、線形判別関数で仕切るという方法もあります。
線形判別関数はマハラノビス距離を活用して算出しますが、マハラノビス距離よりも視覚的に分かりやすいのが特徴です。
上記のように関数でデータを2つに分解できるため、判別したいデータを簡単にグルーピング出来ます。
今回はわかりやすく二次元で表現するために、通知表の成績と期末テストの点数という2つの説明変数を使っていますが、判別分析ではそれ以上の説明変数を利用することもできます。
説明変数の要素を増やせば増やすほど予測は正確になりますが、データもよりばらけるためマハラノビス距離が算出できない可能性があるので注意が必要です。
判別分析とクラスター分析の違い
判別分析とクラスター分析は誤解しやすい分析方法ですが、以下のように本質的には異なります。
判別分析:予測したいデータが2値のどちらに分類されるのかを判別する分析手法
クラスター分析:混ざり合ったデータを近いもの同士でグルーピングする分析手法
機械学習などにおいては、判別分析を「教師あり分析」、クラスター分析を「教師なし分析」と呼ぶ場合があります。
クラスター分析では、全ての要素の距離を算出します。算出された結果はデンドログラムという形で出力されます。
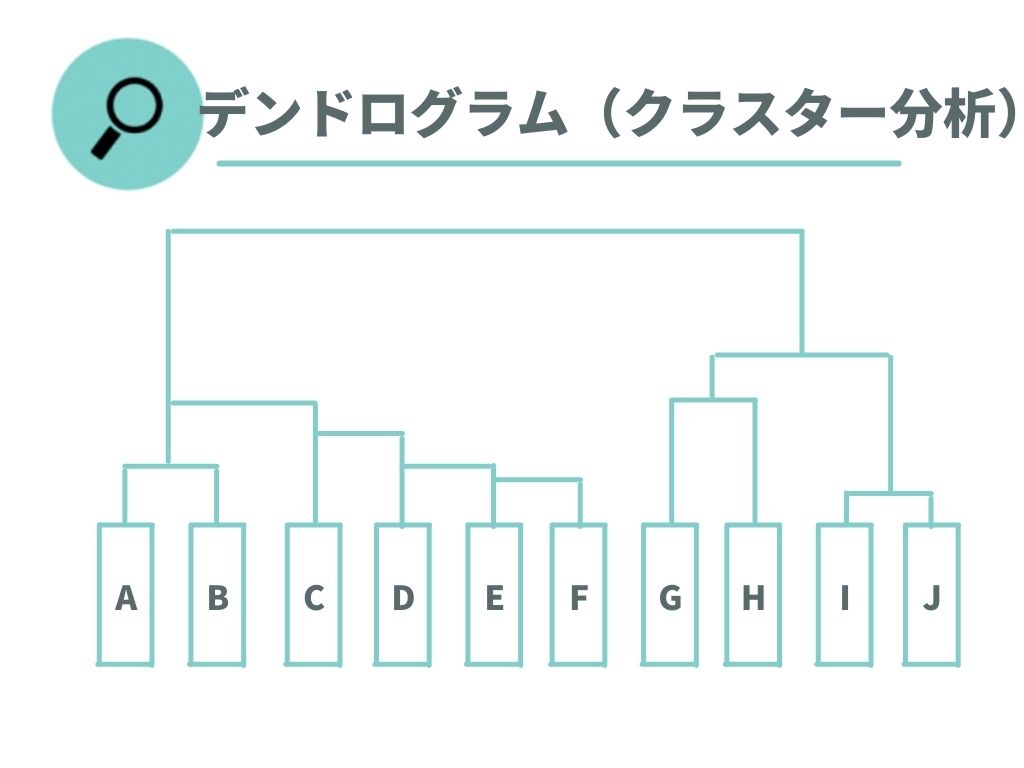
デンドログラムでは、上に線が伸びれば伸びるほど要素が離れていることを示しています。 よって上図で最も距離が近いグループはIとJになり、最も距離が遠いグループがA~FグループとG~Jグループになります。
クラスター分析では事前にグルーピングはせず、結果として出力されるグルーピングに分析者が意味づけを行います。
仮にある会社がクラスター分析を実施し「A、Bグループの顧客が自社商品に興味を持っていそうだ」と意味づけができたとします。
この場合はA、Bグループに近い顧客向けに商品訴求を行うことで、売上増が期待できます。 このようにデンドログラムの距離によって、優先順位の選出に役立ちます。
なおクラスター分析では各要素をユークリッドの距離(三平方の定理)で算出している点も、マハラノビス距離で距離を算出する判別分析との違いといえます。
まとめ
本記事では、判別分析の意味とその活用法を解説しました。 判別分析は企業において以下のようなマーケティング活動に役立ちます。
- リピーターを判断する
- 見込み客の優先順位をつけることができる
- レスポンス広告の顧客属性を調べる
- 併せ買いされやすい商品をレコメンドする
他にも選挙の当選予測や、受験の合否予測など幅広い活用方法があります。
- サービス概要を無料配布中「3分で読めるGMOリサーチ&AIのサービス」
-
GMOリサーチ&AIはお客様のマーケティング活動を支援しており、さまざまなサービスを提供しております。
- スピーディーにアンケートデータを収集するには
- お客様ご自身で好きな時にアンケートを実施する方法
- どこの誰にどれくらいリーチができるか
ぜひこの機会にお求めください。 - 資料請求する

